so few days ago wasted $400 on nano-gpt for their Kimi K2.5 instance, which was super laggy, and i didnt even get any job done so was kinda depressed lol
i mean, was able to build some cool shits but not really directly related to the priority wanted to get done.....
i mean, the whole reason i went for Kimi K2.5 was because of the actual understanding of 3d perspectives, the actual math behind, it, proper color theory logic application and so on
but 2d isometry in canvas2d is way harder for all these llms...
Kimi K2.5 is alright but even on basic things regarding that it's having troubles
but then, yesterday saw Qwen 3.6 Plus Free that was available for limited time for free in opencode
craziness...
like literal actual craziness, in just a couple hours, it made a whole proof of concept, super beautifully designed and whatnot, still needed a few more prompts to fix some actual mechanics that didnt work properly but overall, way better than all the ones that i used this week...
which includes Kimi K2.5 that the Qwen 3.6 even implemented some niche super cool visual features that unlike few days prior, i had to prompt Kimi K2.5 to implement manually...
but then......
sadness...
opencode did a "nvm, Qwen3.6 is now paywalled", i mean, they get paid by those LLM companies to promote their products so they get the newer version that is propietary and so on..
literally sadness tho, only couple hours of work done, only ~200k context reached out the the 1M token size... this shit massive, it can ingest pretty decently large codebases so that's awesome
but yea... paywalled after just couple hours for everyone using opencode, the API wasnt available no more, very sad lol
so then went back to bigpickle and asked what was up with that you now, cause where that opencode manager at or somethin lmao, literally in the middle of 2 hours of work and "nop, paywalled" like fuck that lmao
so anyways, Qwen3.6 doesnt have openweight and whatnot, it's not available to the public
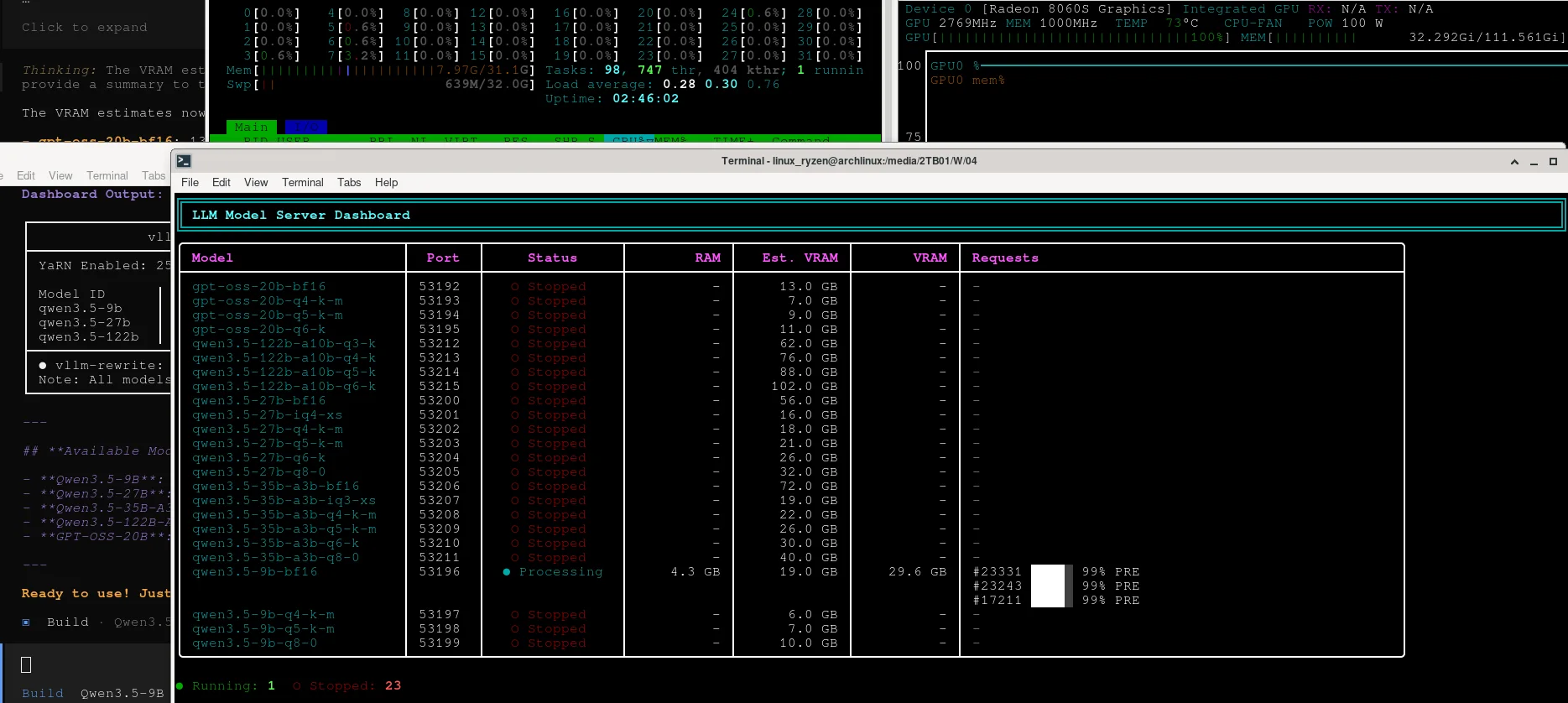
Qwen3.5 however is and can be self-hosted locally, 256k context native for all the variants
tho right now i busy rewriting "llama.cpp" which is 500k lines of code and "vllm" which is a couple hundred thousands lines of code too... cause i cant get to work that "YaRN" thing or whatever the fuck it is so gotta rewrite it all from scratch or somethin to support it i guess.........
well, it's a work in progress in "llama.cpp" but not implemented yet i guess? so idk, will see if the rust rewrite from scratch can make it work that way to be custom built for this hardware too lmao
but pretty much, that "YaRN" thing is what would allow all the quantized variants of Qwen3.5-9B to upgrade their context from 256k context size to 1M context size, so even those small models could have 1M token context size window, well, not just Qwen3.5-9B but also a few others i think 27B or something like that too maybe, forgot which one and forgot to keep the documentation updated on that, but pretty sure either 27B, 35B or both could support the 1M YaRN context window too
@monerica
look, if everything could be run locally then it would be. But who is taking the time to actually explain how to do that without spending a ton of money? You detail how to run an AI as good as the big ones locally then it will be considered.
right now: